
Imagine that you implemented a new intervention in behavioral health intended to improve care or access to care. How can you measure if this intervention was successful? How do you know that the metric used to measure this intervention wasn’t impacted by other variables?
While we have an intuition for whether an intervention had a positive or negative impact, it’s hard to know whether the intervention was the cause of better performance. Consider an example: A community mental health organization implemented telehealth as an option for services to improve access to care. They tracked the number of days between the consumer’s initial assessment and when they received their service, with fewer days between the two being better. This metric was used to indicate whether adding telehealth as an option improved the consumer’s access.
In this example, it seems logical that if the metric shows improved performance after telehealth was implemented, telehealth improved access. However, there may be confounding variables that make the relationship between telehealth and the metric less straightforward. Confounding variables affect both the exposure and the outcome of a model. In the example of telehealth, a confounding variable might be age. A consumer’s age, whether they are a child, teen, or adult, may impact both their ability to utilize telehealth and their ability to receive services quickly. This complicates our understanding of whether telehealth was the cause behind improved performance.
A randomized controlled trial (RCT) is typically considered the best way to eliminate confounding variables, but it’s not always possible to perform a RCT. For example, in healthcare it can be difficult to justify poor health outcomes for consumers randomly placed in a control group since it can be damaging to keep people from receiving treatment.
In some cases, there is plenty of historical data that can be used if the confounders can be taken into account. Propensity score modeling is a tool that can help understand the relationship between an exposure (such as telehealth) and an outcome (such as the time to services metric) while considering any confounders.
Propensity scoring is a type of causal modeling. Unlike predictive modeling, the goal of causal modeling is not to predict the outcome when given a set of variables. Instead, causal modeling is used to understand the relationship between the variables, the exposure, and the outcome. The result of propensity score modeling is the probability that a sample will be in the exposure group while controlling for the remaining variables.
The first and most important step in propensity scoring is to create a directed acyclic graph (DAG) that visualizes the relationship between variables. This is the most important step because propensity scoring depends heavily on the programmer’s knowledge of how each variable relates to each other. To ensure results are as accurate as possible, each step in the development process should consider this information.
A DAG is a graph of nodes that represent each variable connected by arrows, which shows the relationship between those variables. The figure below is an example of a DAG. In our previous example, telehealth would be the exposure node, and the time-to-service metric would be the outcome node.
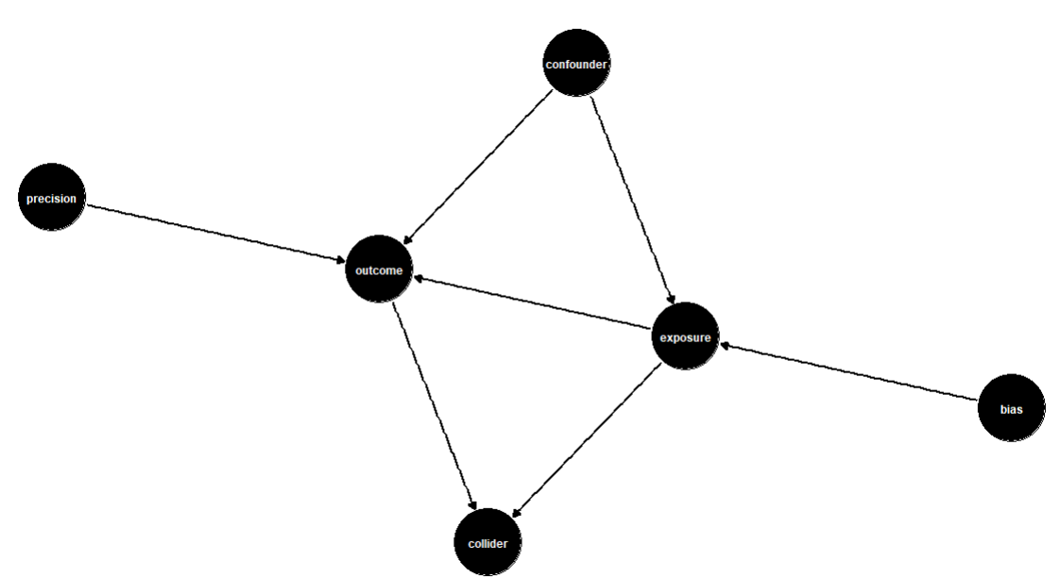
The confounding variables would be anything that affects both the exposure and the outcome. Other variables to include in the DAG are variables that impact only the outcome (precision variables) and variables that are descendants of both the exposure and the outcome (colliders). Variables that affect only the exposure can also be included in the DAG but should not be included in the analysis because they introduce bias into the model.
Once the DAG has been created, it’s time to start modeling. Matching is a modeling type that takes observations from each exposure that match across the remaining variables. For example, one observation would be exposed, and one would be unexposed, but all other variables would have the same value. These two observations would be considered “matched.” This allows the effect of the exposure to be measured directly without the impact of the confounders. The table below shows two matched variables as an example.

There are a few options to modify the matching process to better fit the dataset and context that is being used. First, there are many different matching types that can be used, from nearest neighbor to full matching. The “exact” parameter allows the specification for which variables should be matched on exact values as opposed to similar values. The function also allows the ratio of treated to untreated variables to be specified. This is useful when there are fewer exposed variables than unexposed, and an exposed variable may be matched to more than one unexposed variable.
Once the matched model has been created, the final step is to assess the results and determine an answer to the original question. One simple way to do this is to group the matched data on the exposure and calculate the mean outcome. This will display the mean effect that the exposure has on the outcome variable. In some cases, there may be suspicion that a particular group in a categorical confounder may be affected differently by the exposure than the overall population. In this case, those groups can be investigated by using the same result assessment as before, but with the added grouping of the variable of interest. This will break down the exposure effect further so that different groups can be compared.
By looking at these numbers, it can be determined whether the exposure has a positive or negative impact on the outcome, and how strong that impact is. These results can be used to inform action. In the case of our example, we might find that providing telehealth to a population improves the likelihood that a consumer received services within 14 days of their original assessment. If we wanted to drill down further, we could investigate this across age groups and find that telehealth improves this metric for teens even more than it does for the general population.
These results provide confidence in the effectiveness (or ineffectiveness) of an intervention to improve care or access to care. The results can inform the next course of action, whether that is to support intervention implementation or stop intervention implementation.
Propensity score modeling can provide a better understanding of interventions and their outcomes. This can help organizations make more informed decisions and ensure resources are allocated effectively. If you find yourself trying to understand a complex relationship between an exposure and an outcome, consider propensity score modeling as a solution.
Barrett, M., D’Agostino McGowan, L., Gerke, T. (2024, July 1). Causal Inference in R. Retrieved July 31, 2024, from https://www.r-causal.org/.
Valojerdi, A. E., & Janani, L. (2018, December 7). A brief guide to propensity score analysis. National Library of Medicine. National Library of Medicine (10.14196/mjiri.32.122).
matchit: Matching for Causal Inference (n.d.). RDocumentation. Retrieved August 7, 2024, from https://www.rdocumentation.org/packages/MatchIt/versions/4.5.5/topics/matchit.

The value of analytics is clear, right? Maybe not. Value-creation from data is perhaps the biggest challenge working data scientists face. After all, many highlight the inability of analytics to produce tangible business value. Plenty of articles pinpoint how and why projects go wrong due to factors such as the lack of stakeholder buy-in, inadequate talent, poor data quality, and unclear direction. Given this environment, it’s hard to overestimate the value of incorporating minimum viable products into the project life cycle as soon as possible.
A minimum viable product is a fully operational product containing only the necessary functionality to highlight its core usefulness. The product could be an application, report, or predictive model. Minimal viable products often make the most persuasive case for highlighting the value of analytics to an organization. This also forces data scientists to reckon with data-related challenges earlier, which could affect the project’s value proposition. Value, for all parties, should be the project’s true north. And where value exists, investment follows.
However, generating minimum viable products is a challenging venture. Organizational skepticism often translates into tight budgets, strict deadlines, and clear value-add communication. Under such working conditions, engineering creativity is paramount. It’s in this suspenseful stage of the process that I’ve found tremendous value in tools like Docker and cloud products like Azure Container Instances and Logic Apps. These tools help data scientists stay nimble in producing minimum viable products that can handle production environments. I’d like to share one generalizable use case.
A lot of my analyses start in either R Studio or a Jupyter Notebook and usually take some variant of the following pattern:
The current walk-through example followed that pattern:
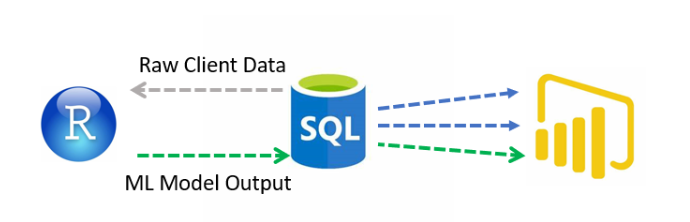
When the entire machine-learning workflow is housed in a single file, the goal is often to schedule the file on a recurrent basis. While useful options exist in Azure for executing machine learning workflows, many of the use cases shared by Microsoft and others assume large-scale infrastructure requirements, relatively straightforward modeling, and a desire to integrate a full-blown CI/CD pipeline. These options are all legitimate areas of development but are not conducive to a minimum viable product.
Analytics in a Behavioral Health Care Organizations
The value proposition is straightforward: When a clinician needs to create a personalized service plan for an individual seeking services, they’d like to view what treatment options were recommended to individuals in the past with a similar clinical and demographic profile.
A clustering algorithm is employed to group clients together with similar characteristics. The resulting model output and custom metrics are merged with other datasets and staged in a SQL database for use in PowerBI. However, the value proposition requires that the process run daily.
Running model scripts daily
The following setup tackled the challenges of running jobs with database credentials, custom compute, cost control, and highly customized analyses all in a fast and cost-effective manner.
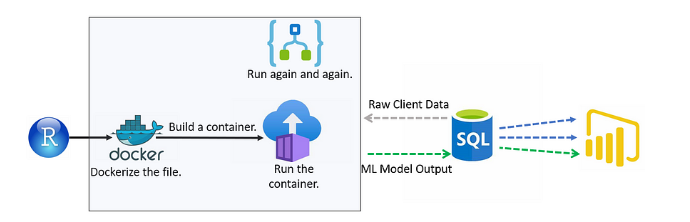
A few notes on the architecture:
Conclusion
Value-creation is the goal to which all work efforts should be aimed, and minimum-viable products help to achieve this purpose. The workflow presented is generalizable to a wide range of use cases faced by working data scientists.
Sources

Imagine this for a moment. You have been experiencing some unsettling symptoms and are struggling to know what is real and what is not. Your friends and family convince you to get some help, and you go to a local behavioral health organization where you are prescribed a medication that falls into the Second-Generation Antipsychotics (SGA) category1. This drug helps with your with your symptoms and allows you to feel some sense of normalcy, however, you are now experiencing symptoms of diabetes. A scary situation resulting in a trip to the ER confirms that you do, in fact, have Type 2 diabetes, and it could be a side effect of the medication you’re on. Now, you need both behavioral and physical health care regularly and could face severe health consequences or premature death. That is a lot of serious life changes to manage, and it is hard to imagine how there could be an approach to this in which anyone wins.
While this may not happen to everyone, it is not an unusual situation. It is estimated that people on SGA medications have at least twice the risk of developing Type 2 diabetes2, and the World Health Organization reports that people with severe and persistent mental illness have a staggering 10- to 20- year reduction in life expectancy compared to the general population3. Reasons for this include medication side effects, barriers to accessing treatment, physical inactivity, and high rates of tobacco or alcohol use.
In the past, behavioral and physical health care were kept separate in the treatment world. This resulted in people bouncing between providers with little communication about overlap in conditions. Now, funding sources, governing bodies, and regulatory agencies are incentivizing models of coordinated care to address this issue. So how does a system set up to be very one-dimensional shift to incorporate other disciplines? Frameworks4 for integration typically include care coordination and care management as part of the solution.
How do we incorporate framework into real life– particularly in this era of staffing shortages and red tape? Companies have to get creative in developing successful care coordination strategies. TBD Solutions recently worked with a CCBHC to create a system that utilizes data to assist care coordinators (sometimes called care managers, case managers, etc.) in prioritizing need. The Risk Factor Queue uses documents in a person’s chart to identify potential risk factors and calculate an overall risk score. Risk factors are categorized into physical, behavioral, and medication-related buckets. Complexity of need increases as the number of identified risk categories increase.
In our earlier example about developing Type 2 diabetes, you would have, at minimum, risk factors noted for your diagnosis and your medications, resulting in a score that is higher due to its complexity. The care coordinator does not need to read through your chart to find all the areas you may need help managing; it is readily available in one spot. Now they can use that information to inform decisions and discuss potential care needs with you. A conversation might look like this,“You don’t have a primary care physician on record? Let’s get you set up with one. You are out of refills on your prescriptions? We will make an appointment to review your medications and refill what is needed.”
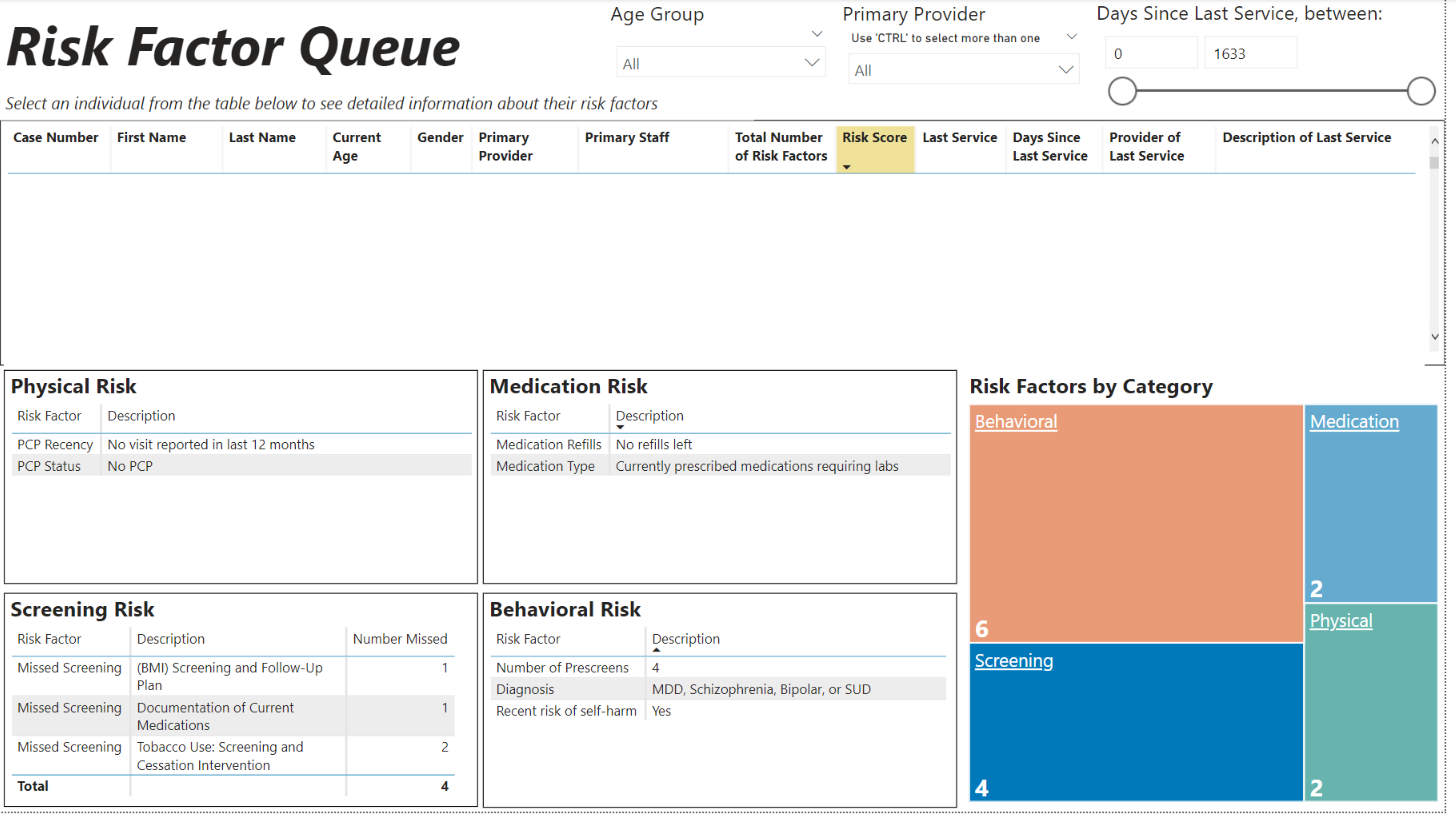
Integrated care doesn’t require people to have expertise in behavioral and physical health care practices, but it does require that processes and systems be put in place to address the clear relationship between physical and behavioral health. Creative solutions must be developed to meet specific needs and incorporate the organization’s strengths. In this case, the need for efficiency from all involved parties was addressed. The care coordinator doesn’t have to spend as much time digging for information in the hopes, they are not missing a client5 who could benefit from their service, and you (the client) aren’t trying to manage your complex needs alone. This is a win-win-win in the eyes of the client, the care coordinator, and the continued quest for integrated care.

From Healthy People 2030 to CCBHC to organization-level strategic planning, a common theme across behavioral and physical health care today is a push for greater equity. This often takes the form of initiatives to better understand the social determinants of health and disparities between populations. This is certainly not the first push for health equity, though; studies of health disparities can be found as early as the mid-1800s. Even with an increase in focus during recent decades, the past 20 years have seen very little progress made toward health equity. While only part of a broader solution, one way organizations can better support current equity efforts is to improve the way we analyze disparities.
Unfortunately, instead of leading to meaningful change, disparities analyses have the tendency to simply reinforce what we already know about the world. Findings are often too broad for one organization to take action on or not nuanced enough to describe a community’s unique characteristics. This is especially true if not enough attention is paid at the beginning of an analysis, before any numbers are crunched. This article outlines a few things you can do when initiating a new disparities analysis to make sure your findings are actionable and meaningful for your community.
Start broad.
Perhaps you are interested in assessing whether there are disparities in access to behavioral health services at your organization. It can be tempting to dive right into available data sources, calculating standard measures by race, sex, and age and churning out visuals. Taking this approach, however, can lead to missed opportunities to better understand the people in your community. Instead, practice starting from the broadest view, considering the full scope of the question and the environment in which you are asking it.
You might start by considering: Why might some populations have an easier time accessing services than other populations?
Next, take note of existing sources of knowledge: What does your own experience tell you about who may not be receiving the services they need and why? What have your colleagues noticed? What are other experts, journalists, and community leaders saying about this topic?
By stepping back and starting broad, you let real people and experiences drive your analyses, and avoid moving too quickly into a line of questioning. You create openings for new perspectives and questions that a narrower lens might have otherwise missed.
Document the specific question(s) you are trying to answer.
Once you identify an area of focus, document the specific question or set of questions you want answered. Questions that are too broad tend to spiral off in many directions and can lead to answers that don’t address the original intent of the question. Good data questions are precise, measurable, and lead to either meaningful answers or new questions.
Broad question: Are there disparities in access to behavioral health services at my organization?
Data question: Does the number service encounters provided per month at my organization differ by race, neighborhood, or income of persons served?
Throughout the analysis, check in to make sure you are still working toward answering the original question.
Be critical of your data sources.
Once you identify what you want to know and which population groupings are important to include, consider what data is available to you.
Do the population measures in your datasets accurately represent and describe your populations of focus? Was race data self-reported or observer-coded? What response options were available? Variation exists in racial/ethnic categories used in reporting, even at the federal level. Answer options may not fully match how individuals self-identify or individuals may be misclassified on administrative records, leading to data that might not be reflective of your community. Similarly, what answer options were available in your measure of gender? Is it a measure of gender identify or really a measure of sex? How is poverty measured? Even the federal poverty line, a standard measure used for eligibility determination for Medicaid along with numerous other programs, is rife with flaws and could lead to underestimates of need.
What population groupings are missing from your dataset? There are some populations that are often left out of standard reporting, either through exclusion during data collection or a lack of relevant identifying measures. LGBTQ and justice-involved populations are at high risk for behavioral health conditions, yet there is little data available (publicly or otherwise) on their experiences. What are some creative ways that you could reach out to those populations for whom you don’t currently have data?
Because getting nuanced population-level data can be time consuming and challenging, we are often limited to whatever major reports and EHR systems can provide. Where it is feasible, think creatively about how you could enhance or add data sources to better describe your populations of focus. Where it is not feasible, be cognizant–and explicitly state–the limitations of your data.
Map out hypothesized relationships.
After you document specific questions and before the analysis begins, a helpful practice is to map out your hypotheses. While often skipped, this step can play an important role in making sure your findings are interpreted in context and can lead to action.
Consider how, specifically, the population measure you are interested in is related to the outcome. Continue asking how until you feel you can clearly draw the line from one variable to the other. Create a mental framework, or better yet, physically draw out the relationships.

The intermediary variables you identify in this process are often more actionable than the initial population measure. Consider how you might include these concepts in your analysis, whether in the first iteration or as part of a refinement process. Do you have data related to these variables? Could these concepts inform qualitative efforts, where you are reaching out and getting input from the individuals who belong to this population?
These hypothesized relationships add important context for interpreting and presenting your findings as well. Too often, results from disparities analyses are misinterpreted in ways that perpetuate the discrimination faced by marginalized populations. Findings of racial disparities are frequently communicated as “the effect of race on _____”, drawing a direct causal link between race and an outcome variable. Mapping out the full pathway, however, we would see that race is a strong predictor of outcomes because it is an “excellent measure of exposure to racism”. Racism is what feeds disparities in housing, education, wealth, and employment, which in turn fuel physical and behavioral health disparities. Without this context, differences in outcomes between racial groups are too often misinterpreted as stemming from a biological difference–a theory with its roots in slavery. Mapping out relationships between population measures and outcomes draws focus to the social factors which drive disparities.
By starting broad, documenting the specific question(s) you are trying to answer, being critical of your data sources, and mapping out hypothesized relationships, your analyses are more likely to result in findings that you can take meaningful action on, creating a clearer path to equity in your organization and your community.



